
DBA Myths: An index on a bit column will never be used.
4February 17, 2014 by Kenneth Fisher
Not true. (Or I guess probably wouldn’t be posting about it would I?)
Probably the first thing I should point out is that just because you can doesn’t mean you should. I can only think of a few very edge cases where an index on just a bit column would be appropriate. Not even if you add a few included columns. Primarily if a bit column is going to be part of an index it should be just that, part of a bigger index.
On top of that I realize that some people really dislike bit’s. Personally I disagree. I think they are a datatype like any other. I’m not going to waste space on a tinyint or char(1) when a bit will do. Now don’t get me wrong, I’m also not going to use them when they are not appropriate either.
And on to a quick proof:
-- Set up code CREATE TABLE BitIndexTest (Id int NOT NULL identity(1,1), myBit bit) CREATE INDEX ix_BitIndexTest ON BitIndexTest(myBit) GO
-- Load data INSERT INTO BitIndexTest VALUES (0) GO 100 -- Warning, this can take a while to run INSERT INTO BitIndexTest VALUES (1) GO 2000000 UPDATE STATISTICS BitIndexTest GO
-- Run query SELECT * FROM BitIndexTest WHERE myBit = 0 GO
And here is the execution plan. Notice that there is an index seek using the index on the bit column.
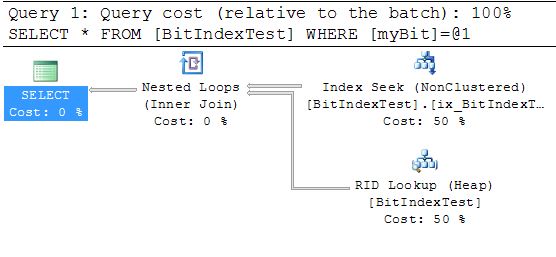
-- Cleanup code DROP TABLE BitIndexTest
Now this is a bit of an edge case. A small number of rows with one value and a large number with the other. If it had been a much higher percentage then you get a table scan instead of an index seek. In fact if you up the number of 0’s to 1000 then it switches over to a table scan. If you include (id)to the index then it will use the index longer but I couldn’t say for certain how much longer.
Again this an edge case. And because it bears repeating, just because you can create an index on just a bit column doesn’t mean you should. If you are using SQL 2008 or higher then a better solution to the same problem would be a filtered index. I still wouldn’t put a filtered index on the 90% side of a 10/90 split. I probably wouldn’t put one on a 50/50 split for that matter. But if you are going to pick one or the other a filtered index is the better solution.





Hi Kenneth,
When i tested it, actual execution plan told that Missing Non clustered Index..(mybit) include (ID) and table scan occured. But you told that we will get table scan if we up the number of 0’s to 1000. What went wrong in my case?
Regards,
Prakash
Actually I said that at 100 I got an index seek and at 1000 I got a table scan. I didn’t really try to narrow down the cross over point. 1st confirm that you only have ~100 0s and ~2mil 1s. 2nd update statistics again. If you are still getting a table scan I can’t really say why. Like I said it’s an unusual edge case. You may be using a different version of the engine than I am. I tried on 2008R2 and 2012 but no service packs on either.
I am also getting the same message that Prakash mentioned above.
That is the same plan I get once I cross over a certain threshold. Just out of curiosity are you running each piece of code separately or all together?