
The clustered index columns are in all of the non clustered indexes.
13July 30, 2014 by Kenneth Fisher
Did you know that whatever columns you pick as your clustered index will be included in any non clustered indexes on the same table? But don’t take my word for it. Let’s take a look!
First things first I’m going to use some AdventureWorks2012 tables to make a test table.
-- Create a convinent composite table SELECT Pers.BusinessEntityID, Pers.Title, Pers.FirstName, Pers.MiddleName, Pers.LastName,Addr.AddressLine1, Addr.AddressLine2, Addr.City, Addr.StateProvinceID, Addr.PostalCode, Addr.SpatialLocation INTO People1 FROM AdventureWorks2012.Person.Address Addr JOIN AdventureWorks2012.Person.BusinessEntityAddress BEA ON Addr.AddressID = BEA.AddressID JOIN AdventureWorks2012.Person.Person Pers ON BEA.BusinessEntityID = Pers.BusinessEntityID GO -- Add indexes including a non-unique (important later) clustered index CREATE CLUSTERED INDEX ix1_People1 ON People1(AddressLine1, AddressLine2, City, StateProvinceID, PostalCode) CREATE INDEX ix2_People1 ON People1(BusinessEntityID) CREATE INDEX ix3_People1 ON People1(LastName, FirstName, MiddleName) GO
The clustered index (CI) is on the 5 address columns and there are non-clustered indexes (NCI) on the BusinessEntityID and the 3 name columns. We can look at the structure of a page from one of the indexes by using sys.dm_db_database_page_allocations and DBCC PAGE (links are in the code below).
-- Get the page id for NCI ix2_People1
-- Info on sys.dm_db_database_page_allocations:
-- http://www.jasonstrate.com/2013/04/a-replacement-for-dbcc-ind-in-sql-server-2012/
SELECT indexes.name, indexes.index_id, indexes.type_desc,
pages.allocated_page_file_id, pages.allocated_page_page_id, pages.is_iam_page
FROM sys.indexes
JOIN sys.dm_db_database_page_allocations(DB_ID(), OBJECT_ID('People1'), NULL, NULL, NULL) pages
ON indexes.object_id = pages.object_id
AND indexes.index_id = pages.index_id
WHERE indexes.name = 'ix2_People1'

In order to use DBCC PAGE I need the file id and the page id. I’m using page 288 instead of 638 because page 638 is the IAM page. All of my pages are in file 1 (I only have the one data file).
-- View index page -- Info on DBCC PAGE: -- http://www.sqlskills.com/blogs/paul/inside-the-storage-engine-using-dbcc-page-and-dbcc-ind-to-find-out-if-page-splits-ever-roll-back/ -- Turn traceflag 3604 on so we can see the results DBCC TRACEON (3604); -- Take a look at the contents of one of the index pages DECLARE @DBID int SET @DBID = DB_ID() DBCC PAGE(@DBID, 1, 288, 3)

You can see the first 9 (of 217) rows in the page in the image above. You can see that while the BusinessEntityID is the only column I indexed on (and the only one that will show up if you look at sp_helpindex or anything similar) there are actually 6 additional columns in the index. The 5 columns from the CI and the UNIQUIFIER column. In case you are interested the UNIQUIFIER is added any time you have a CI that is non-unique (which is why I deliberately made this one non-unique).
I’m going to stop here and point out that I created a clustered index not a primary key. A primary key is by default a unique clustered index but it doesn’t have to be. It has to be unique but not clustered. Because it has to be unique if you create a primary key for your CI then you won’t see the uniquifier column when you look at the page information.
I deliberately created a long clustered index on columns that probably shouldn’t be used as the clustered index to demonstrate a couple of points. First your CI choice is going to affect the size of your indexes.
To start I’m going to create another table (exactly the same) with a different, smaller CI.
-- Create a convinent composite table SELECT Pers.BusinessEntityID, Pers.Title, Pers.FirstName, Pers.MiddleName, Pers.LastName,Addr.AddressLine1, Addr.AddressLine2, Addr.City, Addr.StateProvinceID, Addr.PostalCode, Addr.SpatialLocation INTO People2 FROM AdventureWorks2012.Person.Address Addr JOIN AdventureWorks2012.Person.BusinessEntityAddress BEA ON Addr.AddressID = BEA.AddressID JOIN AdventureWorks2012.Person.Person Pers ON BEA.BusinessEntityID = Pers.BusinessEntityID GO -- Add indexes including a non-unique (important later) clustered index CREATE CLUSTERED INDEX ix1_People2 ON People2(BusinessEntityID) CREATE INDEX ix2_People2 ON People2(AddressLine1, AddressLine2, City, StateProvinceID, PostalCode) CREATE INDEX ix3_People2 ON People2(LastName, FirstName, MiddleName) GO
I’m now going to use a modified version of a query I got off of Basit’s(b/t) blog.
Note that ix1 in both cases should be about the same. The CI IS the table. It contains all of the data for the table so there shouldn’t be any significant change in size. The second index (ix2) is also going to be about the same size. I just swapped the two sets of columns so both ix2s are going to contain BusinessEntityID, AddressLine1, AddressLine2, City, StateProvinceID, and PostalCode. The third index (ix3) on the other hand should show a fairly significant difference. The table People1 will have the columns LastName, FirstName, and MiddleName & AddressLine1, AddressLine2, City, StateProvinceID, and PostalCode while the table People2 will have columns LastName, FirstName, and MiddleName & BusinessEntityID.
SELECT OBJECT_NAME(i.object_id) AS TableName, i.[name] AS IndexName
,SUM(s.[used_page_count]) * 8 AS IndexSizeKB
FROM sys.dm_db_partition_stats AS s
INNER JOIN sys.indexes AS i ON s.[object_id] = i.[object_id]
AND s.[index_id] = i.[index_id]
WHERE OBJECT_NAME(i.object_id) IN ('People1','People2')
GROUP BY OBJECT_NAME(i.object_id), i.[name]
ORDER BY OBJECT_NAME(i.object_id), i.[name]
GO
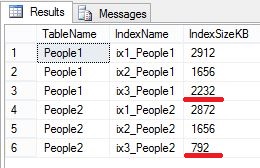
So exactly what I expected. ix1 & ix2 are about the same size in both tables. However ix3 for table People1 is about three times the size of ix3 on People2. Not a big deal with a small table with only 3 indexes. You get to a mm row table with 5 or 6 NCIs it could get rather significant.
Now on an up note with a larger clustered index you do get increased coverage.
SELECT FirstName, LastName, AddressLine1, AddressLine2, City, StateProvinceID, PostalCode FROM People1 WHERE LastName LIKE 'A%' AND AddressLine2 IS NOT NULL SELECT FirstName, LastName, AddressLine1, AddressLine2, City, StateProvinceID, PostalCode FROM People2 WHERE LastName LIKE 'A%' AND AddressLine2 IS NOT NULL
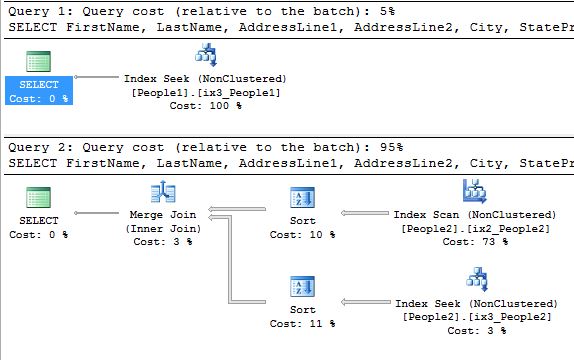
I realize it’s a bit of a goofy query but it does demonstrate the point. In People1 where the CI contains the address information the optimizer was able to use ix3 as a covering index. In People2 where the CI is the BusinessEntityID the optimizer had to use both ix2 and ix3 and ended up taking 95% of the combined time of the two queries. Since the columns in the CI are in all indexes they can always be used when determining if the index covers a query.
Now in my opinion these are not primary reasons for picking out a clustered index. They are more consequences of a CI choice. Important consequences admittedly. Hopefully though, this does point out some of the reasons why picking out the CI for a table is at once very important and very tricky.





I find it intresting and usefull.
Thank you.
Glad you liked it. I found it rather interesting when I learned about it myself.
That’s a great writeup on how to view page contents. But the concept is not new–it’s documented in books online (has been from the beginning) and the idea is one any designer should be familiar with. This is why a small artificial key for a clustered index is very useful when you have many non-clustered indexes on a table–it makes the lookup from the index back into the table data page much faster. A table with non-clustered indexes and no clustered index won’t have any clustered key-values stored at the index leaf entry and any requests for no-covered columns from the index will result in a larger hit than if you had a clustered index.
There’s a lot that goes into efficient database design. I wish more people took an interest in studying up further and learning more about how MS SQL does what it does. Keep it up!
(here’s a BOL link to SQL 2000 that documents that the clustered key values are stored in the index leaf entry: http://technet.microsoft.com/en-us/library/aa933131(v=sql.80).aspx).
I absolutely agree it’s nothing new. Of course if I only wrote about things I couldn’t find in BOL or other blogs I wouldn’t have much to write about 🙂
I’m not sure I agree that an artificial key is always the way to go though. My preference is an incremental date column if one is available of sufficiently high cardinality (even if it isn’t unique). Particularly if it is one that is frequently used in query ranges. However again this isn’t a hard and fast rule. It really depends on the table structure and the expected data. I’m not someone who stands on either side of the natural vs artificial key debate. I’ll use whichever makes more sense at the time. As you said the more you understand about how MS SQL works the better, more informed, decision you can make.
Thanks for the comment and the compliments! I’m glad you enjoyed the post.
The fact that you know that the cluster key is part of the secondary indexes does not mean that you really take this into account in your thinking when you only perform occasional tuning or design work. It is good to be reminded of this fact and to see the effect. Fine article on what we already ‘know’.
Thanks. I don’t figure most people will remember this every time they design a table (lord knows I don’t). I’m just hoping it helps every now and again.
I would find it useful to note that while the cluster key will always be stored at the leaf level of an index (if a clustered index exists), it will only be included at other levels of the index if the non-clustered index key is not unique.
Sorry for the slow reply. I wasn’t aware of this and really want to test it out before replying with anything meaningful, I just haven’t had time yet. I didn’t want you to think I had ignored your comment.
No problem. Here is a quote from Paul Randall at sqlmag.com – “If the nonclustered index is unique, then only the columns defined by the nonclustered index must be in the tree. However, if NC1 had been non-unique then the clustering key would have had to have been added to the tree for navigation.” (http://sqlmag.com/blog/entire-clustering-key-duplicated-nonclustered-indexes)
I believe Kendra Little (or maybe it was Jes Borland) had an indepth post about this too, but I couldn’t find it after a brief search. If I get more time later today, I will try to track it down. It contained a great script to show you what all columns were included in the tree levels of non-clustered indexes.
[…] certainly hadn’t planned on creating a part two of my post on clustered index columns but in the comments Jeremy Hughes pointed out that my understanding was if not incorrect, […]
[…] to be rebuilt. This is because the clustered index columns are in each non clustered index. (Read here and here.) Since the rebuild doesn’t require changing the clustered index this doesn’t […]
[…] index (if there is one). (Clustered index columns are included in the non-clustered indexes Part 1, Part […]
[…] Frequently (but not always) costs additional space. Even though the artificial key is an additional column it’s frequently smaller than a natural key. Because of this when it’s repeated in other tables additional space will be taken up. Also remember if the primary key is also the clustered index then it’s going to exist in every other index. […]