
Triggers are not toys!
9September 17, 2014 by Kenneth Fisher
For the love of all that’s SQL, triggers are not toys! I’m not even talking about logon triggers or DDL triggers. I’m talking about plain old ordinary DML triggers.
Triggers are very useful tools but can easily cause all sorts of headaches. In fact I would generally advise against using a trigger unless there is no other good solution AND you know what you are doing. I recently ran across a trigger that was a stellar example of what not to do. Because of this I want to show you a simplified example of this poorly built trigger and go over some of the things that were done wrong.
I’m using Adventureworks2012 for my example.
-- Set up a log file for later SELECT TOP 0 *, getdate() AS LogDate INTO Production.ProductInventoryLog FROM Production.ProductInventory; GO -- Trigger code CREATE TRIGGER upd_Production_ProductInventory ON Production.ProductInventory INSTEAD OF UPDATE AS DECLARE @ProductID Int DECLARE @LocationID Int DECLARE @ModifiedDate datetime SET @ProductID = (SELECT ProductID FROM inserted) SET @LocationID = (SELECT LocationID FROM inserted) SET @ModifiedDate = GETDATE() IF EXISTS (SELECT * FROM inserted) INSERT INTO Production.ProductInventoryLog SELECT @ProductID, @LocationID, (SELECT Shelf FROM deleted), (SELECT Bin FROM deleted), (SELECT Quantity FROM deleted), (SELECT rowguid FROM deleted), (SELECT ModifiedDate FROM deleted), GETDATE() UPDATE Production.ProductInventory SET Shelf = (SELECT Shelf FROM inserted), Bin = (SELECT Bin FROM inserted), Quantity = (SELECT Quantity FROM inserted), ModifiedDate = GETDATE() WHERE ProductID = @ProductID AND LocationID = @LocationID
To be fair I’ve toned this down a bit from the trigger I saw. Even so I’m hoping you can see there more than a few issues here. Basically this trigger is intended to log the changes and make sure that the modified date is set to GETDATE().
Let’s start with this little bundle of joy:
SET @ProductID = (SELECT ProductID FROM inserted)
First of all let me say if I see this pattern in your code (even when not in a trigger) I will come over and beat you with a wet noddle. The important problem here is that if there is more than one row in inserted then you are going to see the following error:
Msg 512, Level 16, State 1, Line 2
Subquery returned more than 1 value. This is not permitted when the subquery follows =, !=, <, , >= or when the subquery is used as an expression.
This error could be avoided by using the following pattern:
SELECT @ProductID = ProductID FROM inserted
No error this time, even if there is more than one row in inserted. However this causes a different problem. Let’s say inserted has two rows with ProductIDs 1 and 2. There’s no inherent order in SQL Server so which one ends up in @ProductID? ORDER BY, MIN and MAX are probably going to be your best bet to decide which value you want.
Unfortunately, we don’t just have one of these problem children, we have several. This doesn’t just add to our problem it multiplies it. Let’s say we have a table that looks like this:
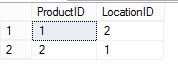
We now run our code to pull the two values
SELECT @ProductID = ProductID FROM inserted ORDER BY ProductID SELECT @LocationID = LocationID FROM inserted ORDER BY LocationID
Gah! Our variables now look like this:
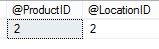
We have values from two different rows! But it gets even worse! The next piece of code is to save the old values into a log table. Great idea, very poorly executed.
IF EXISTS (SELECT * FROM inserted) INSERT INTO Production.ProductInventoryLog SELECT @ProductID, @LocationID, (SELECT Shelf FROM deleted), (SELECT Bin FROM deleted), (SELECT Quantity FROM deleted), (SELECT rowguid FROM deleted), (SELECT ModifiedDate FROM deleted), GETDATE()
First it’s checking to see if there is a row in inserted. Guess what, this is an update trigger. I promise, there is at least one row in inserted. Deleted too but that isn’t relevant at this point. Next we have that same subquery pattern that assumes there will only be a single row being updated at any time. This is bad enough but if you look you will also notice that ProductID and LocationID are being pulled from inserted and the rest from deleted. What happens if one of these columns was updated? Well, to be fair they shouldn’t be because they are the primary key. I’m still not thrilled that they are being pulled from inserted while the rest of the data is pulled from deleted. Either way the logging should look like this:
INSERT INTO Production.ProductInventoryLog (ProductID, LocationID, Shelf, Bin, Quantity, rowguid, ModifiedDate, LogDate) SELECT ProductID, LocationID, Shelf, Bin, Quantity, rowguid, ModifiedDate, GETDATE() FROM deleted
This way every row that is changed is going to go into the log and all of the values are from the same system view. If you do it this way you will also have to modify the query/trigger when you make a change to the table but that isn’t really a big deal. You could remove the column list from the INSERT INTO clause and change the field list to a SELECT * to avoid the problem.
INSERT INTO Production.ProductInventoryLog SELECT *, GETDATE() FROM deleted
Unfortunately if you do and forget to change your log table when you change your primary table it becomes a breaking change. In other words if you add a column to Production.ProductInventory and forget to change the associated log table your trigger is going to break and you won’t be able to do your update. I consider it better to risk losing a little bit of data (the new column) rather than breaking my app. It is however a decision your development team should make and stick to whichever way you go.
Last but not least.
UPDATE Production.ProductInventory SET Shelf = (SELECT Shelf FROM inserted), Bin = (SELECT Bin FROM inserted), Quantity = (SELECT Quantity FROM inserted), ModifiedDate = GETDATE() WHERE ProductID = @ProductID AND LocationID = @LocationID
And here we come to the piece of code that led me to this fiasco to begin with. First we have the same aggravating problems from the previous query. It’s again only written for one row being updated at a time. This is a major flaw in a trigger and needs to be harped on. Your trigger should ALWAYS work whether it’s one row being modified or 1000’s or more. We also have the subqueries for each column again, but this time the author compounded the problem by using the variables (remember above?) to specify which row to update. They are the primary key so only one row at a time can be updated, period. Let’s remove these problems and see what it looks like:
UPDATE Production.ProductInventory SET Shelf = inserted.Shelf, Bin = inserted.Bin, Quantity = inserted.Quantity, ModifiedDate = GETDATE() FROM inserted JOIN Production.ProductInventory PI ON PI.ProductID = inserted.ProductID AND PI.LocationID = inserted.LocationID
We do have a similar problem to the logging query above in that if we add columns to the table they won’t be handled here. This is going to be a flaw in any INSTEAD OF INSERT or INSTEAD OF UPDATE trigger, which is why I generally prefer to just use AFTER triggers when I have to use a trigger at all. In fact in this particular case the call I got was something along the lines of “Every time I update this column nothing happens!” Well the column had been added to the tables but the trigger hadn’t been updated. Fortunately I’ve dealt with this kind of thing before and went straight to sys.triggers to see what triggers were on the table.
Just please remember, if you are going to use a trigger:
- Write your trigger to handle multiple row changes as well as single row changes.
- Be aware what effect changes to your table will have on your trigger.
- Document for the next guy, because not everyone thinks of triggers first!
- Your trigger has to finish before your change (INSERT, UPDATE, DELETE) can finish. If your trigger is slow, your table changes will be slow.
Triggers are tricky things and should only be used when you absolutely need them and even then make sure you are careful!





Well written, much needed reference. I have seen the problem with triggers being designed for a single row many times myself and can understand the confusion they cause when executed in the context of a batch that updates multiple records.
Thank-you for writing it up and sharing with all!
Thanks! Glad you liked it.
I feel your pain. The amount of times I have seen strange behavior in a database only to discover it was a series of triggers firing.
The only thing worse is the liberal use of cursors when a set based solution exists.
No kidding. I actually saw a DDL trigger one time that forced all new database files to go to a certain drive. You wouldn’t believe what a pain that was to find.
[…] stats script for performance and 2014 SQL Server Diagnostic Information Queries for September 2014 Triggers are not toys! Using Geekbench 3.2 To Test Large Database Servers #09 Grant Fritchey, Database Dev Ops When is […]
Thanks for the effort you put into this, Kenneth, it showed — very clear and well done!
Thanks! I have to admit badly written triggers always amuse me 🙂
[…] a recent article by Kenneth Fisher, he describes the process of creating and using triggers, and why they can be […]
[…] All triggers require careful thought before implementing them. Logon triggers in particular are dangerous because they can stop anyone from being able to connect […]