
You can’t use aggregate/windowing functions with CROSS APPLY
11October 6, 2014 by Kenneth Fisher
One of my favorite features of CROSS APPLY is the ability to use it instead of a calculated variable. Well recently I was working on performance tuning a rather annoying query (which I will blog about in more detail later) and one of the steps I took was an attempt to combine CROSS APPLY and a windowing function. As you can tell from the title it didn’t work.
-- Setup code
CREATE TABLE CrossApplyWindow (
Code char(3),
RegionId char(3)
)
GO
INSERT INTO CrossApplyWindow VALUES
('abc','123'), ('def','123'), ('ghi','123'),
('abc','456'), ('ghi','456'),
('abc','789'), ('def','789'), ('ghi','789'), ('jkl','789')
GO
The initial query was pulling a distinct count of codes by regionid.
SELECT RegionId, COUNT(DISTINCT Code) AS Calc FROM CrossApplyWindow GROUP BY RegionId; GO
Simple enough but in this particular case I wanted to do it using a windowing function. Unfortunately COUNT DISTINCT doesn’t work with windowing functions. (Side note: it would be nice if you voted for the connect item in the link.) So after getting some help I ended up using DENSE RANK() and MAX(). Interestingly enough in the case of my query it was much more efficient. My example here is a simplified version of the query, so it may not show any performance improvement. I haven’t actually checked.
SELECT
RegionId,
Calc = MAX(dr)
FROM
(
SELECT
RegionId,
dr = DENSE_RANK() OVER
(PARTITION BY RegionId ORDER BY Code)
FROM CrossApplyWindow
) AS X
GROUP BY RegionId;
GO
So far so good. As part of my tuning effort I tried to get rid of the subquery by using CROSS APPLY.
SELECT RegionId, MAX(x.dr) AS Calc
FROM CrossApplyWindow
CROSS APPLY (SELECT DENSE_RANK() OVER
(ORDER BY Code) AS dr) x
GROUP BY RegionId;
GO
It certainly looks better right? Well here is the output from the previous query.
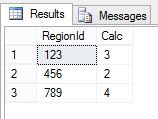
And here is the output from the CROSS APPLY query.
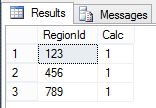
That doesn’t look right does it? Calc is only showing up as 1 for each region when obviously from the data and the previous query we can see that these results aren’t correct. The best I can tell is that CROSS APPLY only receives the row it is associated with. So no windowing functions (or aggregate functions for that matter) will work with it. Here is the best proof I could come up with.
SELECT CrossApplyWindow.*, x.* FROM CrossApplyWindow CROSS APPLY (SELECT Code, RegionId) x; GO






Hey Fisher, I could have approached this way with window functions:
SELECT RegionId, MAX(x.dr) AS Calc
FROM CrossApplyWindow ca
CROSS APPLY (SELECT DENSE_RANK() OVER (ORDER BY Code ) AS dr
FROM CrossApplyWindow caw
WHERE ca.regionid = caw.regionid
) x
GROUP BY RegionId;
GO
That certainly works, but while I could be wrong it looks like you are basically creating an inner join just using a cross apply?
Yeah you are right Fisher. I don’t think it’s possible with just a cross apply.
You are correct that cross apply is effectively called per row, in fact, that was the original intention (to facilitate joining to a table valued function)
Benson’s cross apply certainly works, but using a cross apply here will result in a better plan than an inner join because it limits the set before the join happens.
Quick question though,
Why couldn’t you do the following:
SELECT regionId,COUNT(code)
FROM CrossApplyWindow
GROUP BY RegionId, code
That should effectively give you a count distinct too.
I had realized that the intent of the CROSS APPLY was single row. I was hoping that windowing functions would go outside of that though.
I don’t see any reason why your idea wouldn’t work. I may have to give that a shot. It does have the limitation that if the query is more complex that those 2 columns it may not work properly.
Hey Kenneth and StevenFox,
This query will not give us the correct result
SELECT regionId, COUNT(code)
FROM CrossApplyWindow
GROUP BY RegionId, code
Reason: Grouping on above two columns will give us the the result like this
RegionId Calc
123 1
456 1
789 1
123 1
789 1
123 1
456 1
789 1
789 1
because GROUP BY groups values as distinct from RegionId and Code. Please let me know if I’m wrong.
You are of course 100% correct!
my intention more like the following:
select x.regionId, count(x.regionId)
from
(
SELECT regionId,code
FROM CrossApplyWindow
GROUP BY RegionId, code
) as x
group by regionId
in this case the group by ensures there is only 1 region/code combination, counting the region is equivalent to count distinct.
in terms of query plan, this is the same as the query using count distinct.
ID Rslt1 CO1 Rslt2 C02 ResultTotal
1484 NULL 1 NULL 1 0
1486 NULL 1 NULL 1 0
1487 NULL 1 1 1 1
1494 NULL 1 NULL 1 0
1495 NULL 1 NULL 1 0
1496 NULL 1 NULL 1 0
1499 NULL 1 NULL 1 0
1500 NULL 1 NULL 1 0
1501 NULL 1 NULL 1 0
1502 NULL 1 NULL 1 0
Need your help. This is the table. The goal is to calculate ResultTotal column.
My question is how will I use cross apply in this table where if either of Rslt 1 and Rslt2 columns have 1 then Co1 * rslt1 + Rslt2 *c02. If either Rslt 1 and Rslt2 have NULLs then the product of the two columns is 0.
First of all you are better off posting questions like this to the various forums like http://www.sqlservercentral.com or dba.stackexchange.com. There are a lot smarter people than me available and a lot of them. Your more likely to get an answer more quickly.
My question for you is why are you trying to use CROSS APPLY in this case? I would just use a case statement. Something along the lines of:
Hi Kenneth, I will look at this later today and will come back to you.
Eri, can you try the below if I understand your requirements well.But basically the below cross apply becomes an inner JOIN. If am misunderstanding the requirements let me know then I can quickly fix it…. The case statement might not be the best depending on your dataset as it can be slow for large extracts.
IF OBJECT_ID(‘TempDB..#Temp’) IS NOT NULL
DROP TABLE #temp
CREATE TABLE #temp(ID INT NOT NULL, Rslt1 INT NULL , CO1 INT NOT NULL, Rslt2 INT NULL, CO2 INT NOT NULL, ResultTotal INT NOT NULL)
GO
INSERT #temp
( ID ,
rslt1 ,
CO1 ,
Rslt2 ,
CO2 ,
ResultTotal
)
select 1484, NULL, 1, NULL, 1, 0 union all
select 1486, NULL, 1, NULL, 1, 0 union all
select 1487, NULL, 1, 1 , 1, 1 union all
select 1494, NULL, 1, NULL, 1, 0 union all
select 1495, NULL, 1, NULL, 1, 0 union all
select 1496, NULL, 1, NULL, 1, 0 union all
select 1499, NULL, 1, NULL, 1, 0 union all
select 1500, NULL, 1, NULL, 1, 0 union all
select 1501, NULL, 1, NULL, 1, 0 union all
select 1502, NULL, 1, NULL, 1, 0
SELECT A.ID ,
A.rslt1 ,
A.CO1 ,
A.Rslt2 ,
A.CO2 ,
A.ResultTotal,
T.TestResultTotal
FROM #temp A
CROSS APPLY
(
SELECT CASE WHEN (Rslt1 = 1) OR (Rslt2 = 1)
THEN (CO1 * COALESCE(Rslt1,0)) + (COALESCE(rslt2,0) *CO2)
ELSE 0
END AS TestResultTotal
FROM #temp B WHERE B.ID = A.ID
) T