
Using a date or int column as the clustered index.
13December 1, 2014 by Kenneth Fisher
The other day I was answering a question about clustered indexes and it lead indirectly to a twitter conversation on whether a date or int column was better as a clustered index. My contention is that a date column (if it is appropriate and will be useful) is a better clustered index than the int column. So I decided to do some tests. I want you to know I started these tests not knowing what the result would be (although I suspected) and doing my best to be as unbiased as possible. If you see something I missed or want to throw your two cents into the argument please feel free to comment. FYI By date column I’m including Date, DateTime, DateTime2, etc data types.
Now there are a number of assumptions here.
- The date column is ever increasing (or decreasing). This way we aren’t going to hurt insert speed and we aren’t going to affect fragmentation.
- The date column is not regularly updated. In other words it’s a create date, or order date as opposed to a modified date. This way we won’t hurt update speed and fragmentation.
- The date column may or may not be unique.
- The date column already exists and is not created specifically for this use.
- The date column is commonly used in range queries on this table. (i.e. There is actually a valid point to using the column as the clustered index.)
- The int column is an identity or some other artificial key that is unique and ever increasing/decreasing.
Cons to using the date column
- Date columns are larger causing all of the indexes to be larger.
- Date columns are not usually unique requiring an additional hidden column in the index called a uniquifer that will increase the size of all of the indexes even more.
Pros to using the date column
- The size increases are not that significant as long as there are not a large number of indexes.
- Queries that use ranges on this date will be able to take advantage of the fact that the rows are physically sorted in this order.
Create test tables
I’m using a table from AdventureWorks2014. I’m generating two identical tables with identical indexes with the exception that in one the integer PRIMARY KEY is clustered and in the other the date index is clustered.
SELECT * INTO date_CI_TransactionHistory FROM Production.TransactionHistory; ALTER TABLE date_CI_TransactionHistory ADD CONSTRAINT PK_date_CI_TransactionHistory PRIMARY KEY NONCLUSTERED (TransactionID); CREATE CLUSTERED INDEX IX_date_CI_TransactionHistory_TransactionDate ON date_CI_TransactionHistory(TransactionDate); CREATE NONCLUSTERED INDEX IX_date_CI_TransactionHistory_ProductID ON date_CI_TransactionHistory(ProductID); CREATE NONCLUSTERED INDEX IX_date_CI_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID ON date_CI_TransactionHistory(ReferenceOrderID, ReferenceOrderLineID); GO SELECT * INTO int_CI_TransactionHistory FROM Production.TransactionHistory; ALTER TABLE int_CI_TransactionHistory ADD CONSTRAINT PK_int_CI_TransactionHistory PRIMARY KEY (TransactionID); CREATE NONCLUSTERED INDEX IX_int_CI_TransactionHistory_TransactionDate ON int_CI_TransactionHistory(TransactionDate); CREATE NONCLUSTERED INDEX IX_int_CI_TransactionHistory_ProductID ON int_CI_TransactionHistory(ProductID); CREATE NONCLUSTERED INDEX IX_int_CI_TransactionHistory_ReferenceOrderID_ReferenceOrderLineID ON int_CI_TransactionHistory(ReferenceOrderID, ReferenceOrderLineID); GO
Size
One of the biggest complaints is size. The test table I’m using has ~100k rows, a primary key and three other indexes so we should be able to see a size difference reasonably easily.
EXEC sp_spaceused date_CI_TransactionHistory EXEC sp_spaceused int_CI_TransactionHistory
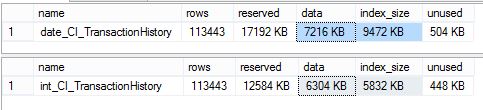
So we have an overall increase of 4.5mb or ~30%. That’s a fairly significant increase in space. It certainly could be an issue in a large system or a system with limited disk space. Fortunately disk space is fairly cheap so it’s less of an issue than it could have been.
Performance
Of course the most important test is going to be performance. I’m going to run four tests. A date range, a specific date, a search on the int column and a join using the int column.
Date range search
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM date_CI_TransactionHistory WHERE TransactionDate BETWEEN '2014-05-01' AND '2014-05-31' SELECT * FROM int_CI_TransactionHistory WHERE TransactionDate BETWEEN '2014-05-01' AND '2014-05-31'
-- Results from date_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (12779 row(s) affected) Table 'date_CI_TransactionHistory'. Scan count 1, logical reads 107, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 16 ms, elapsed time = 387 ms. -- Results from int_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 35 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (12779 row(s) affected) Table 'int_CI_TransactionHistory'. Scan count 1, logical reads 792, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 15 ms, elapsed time = 336 ms.
Not a significant difference in time here (15ms) but a little less than 700 few page reads for the date CI. I would guess that at scale (millions of rows or more) we would start to see an even more significant difference.
Single date search
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM date_CI_TransactionHistory WHERE TransactionDate = '2014-05-05 00:00:00.000' SELECT * FROM int_CI_TransactionHistory WHERE TransactionDate = '2014-05-05 00:00:00.000'
-- Results from date_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 56 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (336 row(s) affected) Table 'date_CI_TransactionHistory'. Scan count 1, logical reads 6, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 153 ms. -- Results from int_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 69 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (336 row(s) affected) Table 'int_CI_TransactionHistory'. Scan count 1, logical reads 792, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 15 ms, elapsed time = 311 ms.
This is where I expected to see the largest difference and I certainly did. The date CI is the clear winner here. 786 less reads and 158ms less elapsed time. If you are going to be a lot of this type of query this could be a really big deal.
Int search
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM date_CI_TransactionHistory WHERE TransactionID = 166032 SELECT * FROM int_CI_TransactionHistory WHERE TransactionID = 166032
-- Results from date_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 43 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (1 row(s) affected) Table 'date_CI_TransactionHistory'. Scan count 0, logical reads 5, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms. -- Results from int_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 1 ms. SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (1 row(s) affected) Table 'int_CI_TransactionHistory'. Scan count 0, logical reads 3, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 0 ms, elapsed time = 0 ms.
No real difference here. Total elapsed time is 0ms for both and the reads are 5 and 3.
Join on the int
I didn’t have another good table to join to so I just joined back to the original table. It should be good enough for demonstration purposes.
SET STATISTICS IO ON SET STATISTICS TIME ON SELECT * FROM date_CI_TransactionHistory CI_Test JOIN production.TransactionHistory Orig ON CI_Test.TransactionID = Orig.TransactionID WHERE Orig.Quantity > 30 SELECT * FROM int_CI_TransactionHistory CI_Test JOIN production.TransactionHistory Orig ON CI_Test.TransactionID = Orig.TransactionID WHERE Orig.Quantity > 30
-- Results from date_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 0 ms. (8726 row(s) affected) Table 'Workfile'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'date_CI_TransactionHistory'. Scan count 1, logical reads 908, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'TransactionHistory'. Scan count 1, logical reads 797, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 32 ms, elapsed time = 424 ms. -- Results from int_CI_TransactionHistory SQL Server parse and compile time: CPU time = 0 ms, elapsed time = 2 ms. (8726 row(s) affected) Table 'TransactionHistory'. Scan count 1, logical reads 797, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. Table 'int_CI_TransactionHistory'. Scan count 1, logical reads 792, physical reads 0, read-ahead reads 0, lob logical reads 0, lob physical reads 0, lob read-ahead reads 0. SQL Server Execution Times: CPU time = 46 ms, elapsed time = 357 ms.
Obviously this one goes to the int CI. A bit faster (67ms) and a few less logical reads (just over 100) but no workfile or worktable involved. Depending on the actual query (and at a larger scale) you could see a larger difference here. If this is your most common type of query you are going to want to use the int CI.
Summary
I saw significant improvement in the date queries with the date CI to go along with the significant increase in table (and index) size. On the other hand there was a small (but very real) decrease in speed when the date column was the CI on queries that used the int column.
In the end I’m right back where I started. If I’m not pressed for space, and my queries use the date column more than the int column then I’m going to make the date column my CI.
Here is what I would like you to take away from this. An identity/int column is not your only choice for the clustered index. Your CI is an important design choice. Take a look at your table and at the queries you expect to run against it. Maybe even load some test data and try a few things. Then make an informed decision.





What if you extend your clustering key to DATE, ID or ID, DATE? I tried it and got some different results. Pasted here for you to review:
http://pastebin.com/J2JUxmb0
Also there’s a typo in your second TransactionID (32 vs. 321)
SELECT *
FROM date_CI_TransactionHistory
WHERE TransactionID = 166032
SELECT *
FROM int_CI_TransactionHistory
WHERE TransactionID = 1660321
Nice addition. I’m going to have to read through that later when I have some more time. I’ve corrected the typo. Turns out it was an HTML problem (I forgot to close my code block).
[…] Data Tools what is devops as explained by nathen harvey SQL Server Quickie #20 – CXPACKET Waits Using a date or int column as the clustered index 8 Ways To Learn SharePoint And Office 365 On A […]
I’m a little disapointed since the article purportedly discusses CIs on columns of type date, but in fact the column is of type datetime.
This is important because of the difference in size between date (3 bytes) and datetime (8 bytes).
I’ve been interested in the discussion in the title (but not in the article) for some time. Kimball usually suggests an integer for a date column but I question the wisdom of that choice sine:
1. It takes an extra byte
2. It is not directly usable as a date (requires conversion)
The difference in using a 3 byte date datatype is actually going to be less significant that it might appear at first. Given that the index will in all probability be non-unique (most date datatypes will end up being non-unique) an additional uniqueifier will be added to the index. This makes it a difference of a 4 byte integer index to a 7 byte (date + uniqueifier) or 12 byte (datetime + uniqueifier) index. If you would like I will run the same set of tests as above using a date and add them to the post. (FYI I have also read the uniqueifier is of variable length so I’m not sure what the actual storage requirements will end up being. )
However it seems you are more asking about storing a date as an integer datatype vs storing a date as a date datatype. I’ve actually done this before and found that the one byte difference in size, while it made a difference, wasn’t all that significant in and of itself. There is however some significant overhead involved in using integers. For example the Date datatypes have a fair number of built in calculations (datediff, datepart etc) that are not available with the integer version, and you will want to convert back to a real date for report formatting. Now I have seen date tables used to good effect but typically on reporting and data warehouse databases and not OLTP type databases.
I found this paper by Kimball http://www.kimballgroup.com/wp-content/uploads/2013/08/2013.09-Kimball-Dimensional-Modeling-Techniques11.pdf and when I looked at the section on “Calendar Date Dimensions” he appeared to be specifically talking about using a date table with an integer surrogate key, again in a data warehouse or OLAP situation. He also mentioned that the surrogate key would be better as an integer representation of the date rather than just a generic incrementing integer.
My opinion would be that you should stick with the Date datatype for OLTP and a date table for OLAP but I’m not an expert when it comes to OLAP or database design in general. I’m going to ask around for some opinions and I’ll let you know what if anything I find out.
Hello Kenneth
Can you please post a link where you read about the variable length of uniquifier?
I ask because i read that it’s a regular 4 byte integer as you mentioned earlier. I have also run a test on this where in a table i have a clustered index on a column and I start inserting rows with the same value in all rows for the clustered index columns.
I got the following error after insert a little over 2.1 billion records
“The maximum system-generated unique value for a duplicate group was exceeded for index with partition ID 72057594041204736.
Dropping and re-creating the index may resolve this; otherwise, use another clustering key.”
Not sure where I read it originally but you can see it here: https://msdn.microsoft.com/en-us/library/ms178085.aspx. It looks like it’s saying it’s either 4 bytes (if the clustered columns are non-unique) or 0 bytes (if the clustered values are unique).
It makes sense that you would get an error there if the uniqueifier is basically an int used to establish uniqueness. Of course that also means that you can have 2 bil duplicates of any particular set of values for your clustering key. (Great test by the way. You should blog that!)
What version of SQL Server are you using for your tests?
SQL 2014 and 2012
Here’s an article about using the Date data type (for a DW dimension) instead of Integer. The author built several tests to compare performance of Date vs. Integer.
http://www.made2mentor.com/2011/05/date-vs-integer-datatypes-as-primary-key-for-date-dimensions/
Aside from speed and size, the best reason of all to use Date instead of Integer for the CI (for DW) is that as a natural key it eliminates the need to join to the date dimension just to find out the date.
Thanks for the link. It made an excellent read. I’m a firm believer in using what’s appropriate at the time. Sometimes it will be a surrogate key, sometimes a natural. I only really get frustrated when people decide it should ALWAYS be one way or the other.
[…] key and the clustered index don’t have to be the same thing. So using something like a modified date as the clustered index and something else as the primary key could be perfectly reasonable. In fact […]
[…] so if you don’t have one spend some time, figure one out and create it. When possible I like dates as a clustered index but of course, it’s highly specific to the table you are working on. There are a few types of […]