
TOP 1 killed my performance; Rob Farley helped me resurrect it.
15March 21, 2016 by Kenneth Fisher
tl;dr; There is no short version of this. It’s LONG. It’s interesting but you might want to skip it if you are in a hurry. If you have the time however, it’s a great walk through of tuning a query.
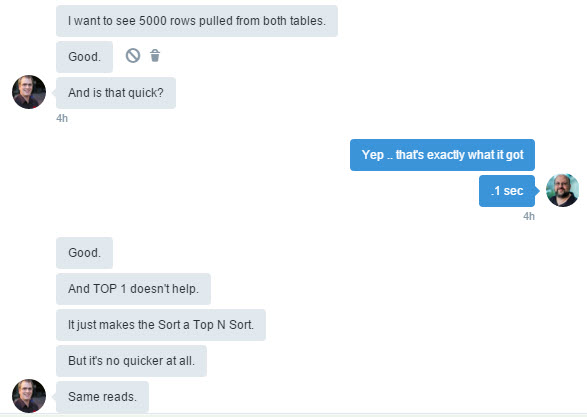
I had a great time today. I was handed a fairly random query by a co-worker/friend and asked if I could help speed it up some. Now after looking at it a bit I decided it was .. odd. Leaving aside any coding issues (it used an old style join) it was SLOW (not done after 12 minutes). But only when it had a TOP 1. If I removed the TOP 1 it ran in about 2 seconds. I realize that certain phrases (TOP, FAST) in a query change the Row Goal (the number rows the optimizer expects to get back or get back quickly) and that can change the query plan, even dramatically, but I had no clue why the big slow down. I decided to ask the experts and put a question into dba.stackexchange. I got a couple of great answers (You should go read them). Certainly better than my initial attempt. Which was to dump the ~5k rows into a temp table and get the TOP 1 from the temp table.
A little while later Rob Farley (b/t) contacted me and started asking a few questions about it. It turned into him walking me through tuning the query. It was an awesome experience and with his permission I decided to share. I took screen shots of the conversation and I’ll go ahead and make comments after each image with my impressions and any information I think would be helpful.
Let’s start by setting up a test environment. Adam Machanic (b/t) gave me a great starting point and I’ve modified it a bit to make it easier to follow along.
USE tempdb GO CREATE TABLE Big_Table (Sort_Id int NOT NULL, Join_Id int, Other_Id int NOT NULL) ALTER TABLE Big_Table ADD CONSTRAINT id PRIMARY KEY CLUSTERED (Sort_Id, Other_Id) GO WITH a AS (SELECT 1 AS i UNION ALL SELECT 1), b AS (SELECT a.i FROM a, a AS x), c AS (SELECT b.i FROM b, b AS x), d AS (SELECT c.i FROM c, c AS x), e AS (SELECT d.i FROM d, d AS x), f AS (SELECT e.i FROM e, e AS x) INSERT Big_Table SELECT TOP(1500000) ROW_NUMBER() OVER (ORDER BY (SELECT null)), ROW_NUMBER() OVER (ORDER BY (SELECT null)) + (CHECKSUM(NEWID()) % 100), 1 FROM f GO -- Index left over from me flailing around CREATE INDEX ix_Big_Table ON Big_Table (Sort_Id, Join_Id) CREATE TABLE Small_Table (PK_Id int NOT NULL IDENTITY(1,1) CONSTRAINT pk_Small_Table PRIMARY KEY, Join_Id int, Other_Col int, Other_Col2 char(1), Where_Col datetime) GO INSERT Small_Table SELECT TOP(5000) Join_Id, 1, 'a', DATEADD(MINUTE, -Join_Id, GetDate()) FROM Big_Table ORDER BY Join_Id DESC GO
Note: If you want to follow along you’ll need to set your cost threshold for parallelism to at least 30 (not sure what the lowest limit is but 30 is what I have) to avoid some parallel plans that you’ll get if it’s at the default 5.
EXEC sp_configure 'cost threshold for parallelism', 30; RECONFIGURE;
Next here is the initial query (cleaned up a little bit and modified to suit the demo).
SELECT TOP 1 ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
JOIN Big_Table BT
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col < = GETDATE()
ORDER BY BT.Sort_Id;
GO
Here is the estimated query plan (remember I never waited for it to finish)
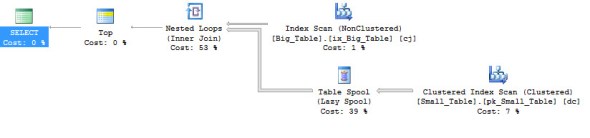
And when I remove the TOP 1 I got this query plan and it ran in 2 seconds.
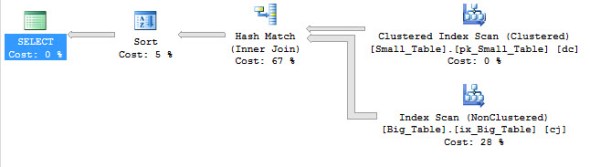
Last but not least here is the initial answer I went with (from the DBA.se question above). I changed the INNER JOIN to an INNER HASH JOIN and it ran in just under a second. I generally try to avoid hints but in this case it seemed acceptable.
SELECT TOP 1 ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
INNER HASH JOIN Big_Table BT
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col <= GETDATE()
ORDER BY BT.Sort_Id;
GO
And here is the query plan.
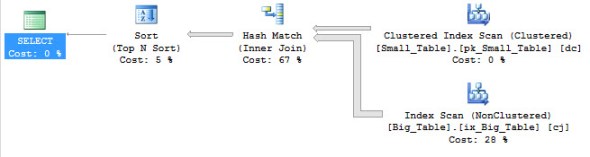
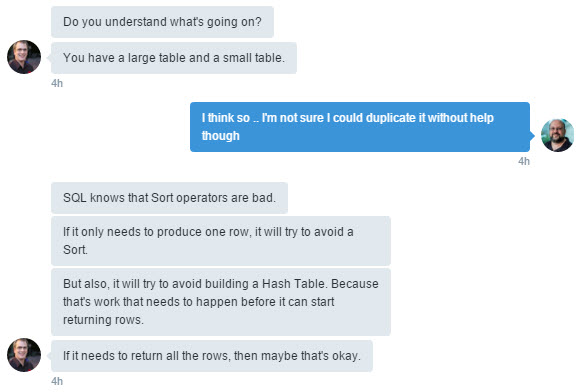
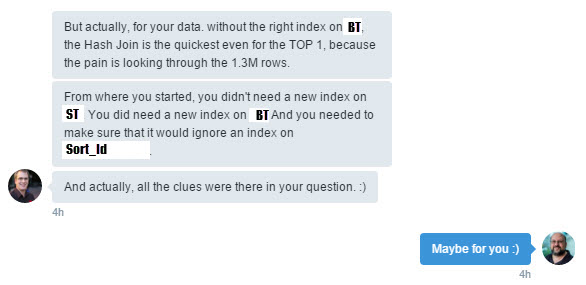
So now we are all at the same starting point. Here is where Rob comes in. I’ve made some obvious changes here and there to what he said so the column and table names match the demo code. Also there was a bit extra in the WHERE clause that I eliminated because it didn’t really have an effect on the outcome.
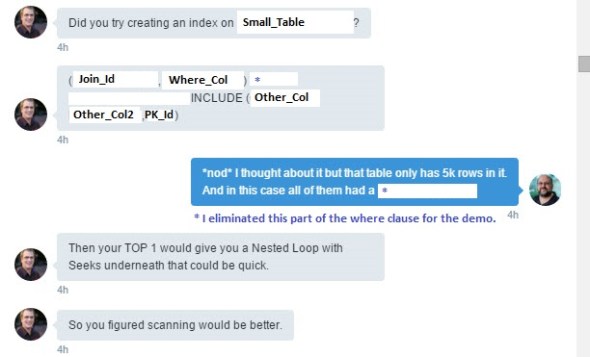
Here Rob suggests an index that I admit I should have thought of myself. I decided the table was so small it didn’t really matter. Silly mistake. While Rob is “talking” I’m trying it out. Note: The index he suggested was a filtered index (it had a WHERE clause). Since I’ve removed that condition from the query I removed it from the index. You’ll see a few references to it at the beginning.
Just in case it’s not obvious, when Rob talks about dive in and try one row what he means is that it’s going to pull the first row of Big_Table (based on the Sort_Id) and then look to see if there is a matching value in Small_Table. The optimizer feels this would be faster than building a HASH TABLE across the entire Small_Table even though it’s fairly small.
Here is the new index I created.
CREATE INDEX ix_Small_Table ON Small_Table(Join_Id, Where_Col)
INCLUDE (Other_Col, Other_Col2, PK_Id)
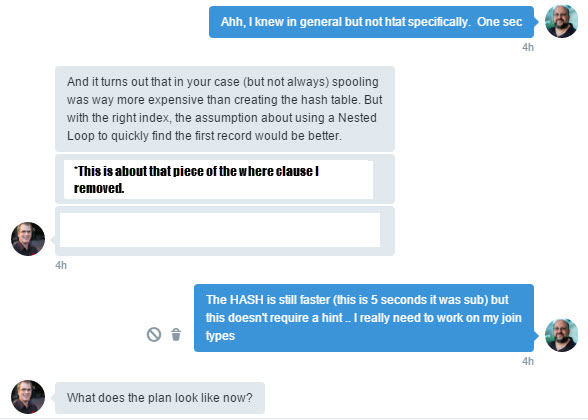
And here is the new query plan. And you get to actually see it. Rob had to put up with my description.
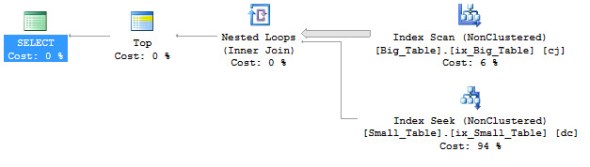
Better, but still a little slower than the initial fixed version that used the INNER HASH JOIN.
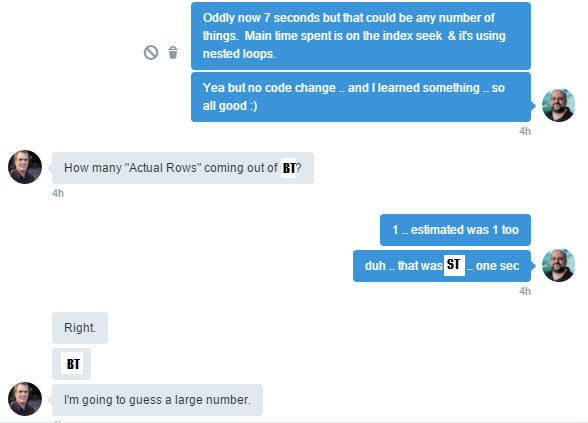
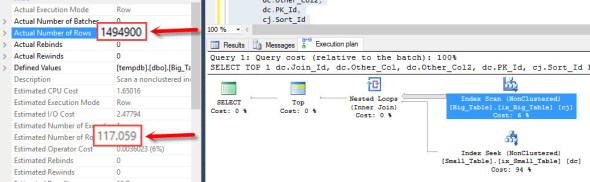
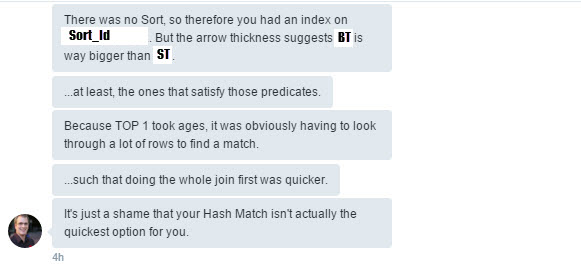
Here we are looking at the difference between the estimated and actual number of rows for an element of the plan. To look at this information you can either mouse over the element or right click and open the properties tab. In this case you will see that the estimated number of rows (what the optimizer thought would happen) is fairly low (117) particularly compared to what actually happened (1494900). When you see a big difference like that in a query plan there is something wrong.
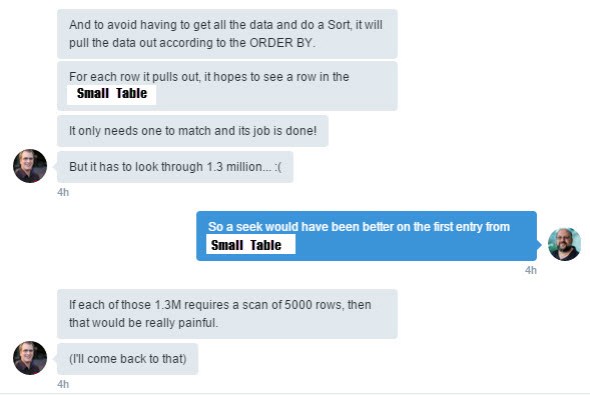
Here we are discussing how the current plan works. Top 1 makes the optimizer think that it will get the answer quickly. So it loops through the Big_Table (it being the table that’s ordered) and then looks into Small_Table to see if there is a match. And as Rob says if that look into the Small_Table is a scan across 5000 rows it could take some time.
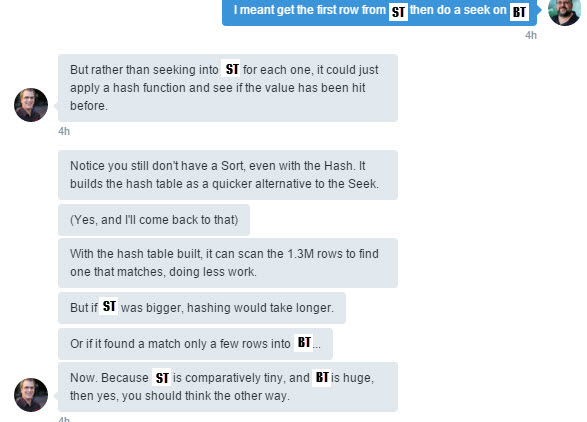
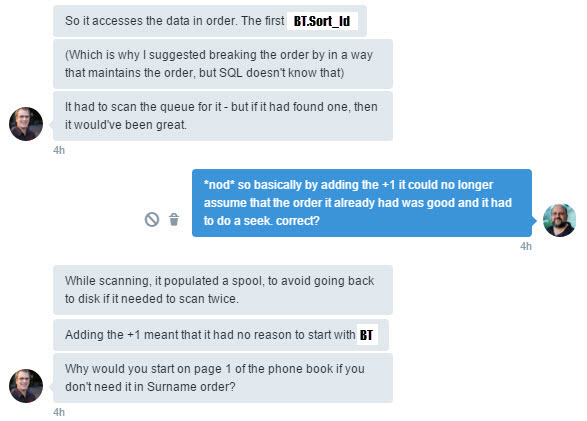
Here Rob starts describing a way to look at how the optimizer works. You can pretend it’s just paper and start using logic. In this particular case looking through a phone book, to say find someone on a particular street. Rob also suggests adding 1 to the sort order. (I’m particularly impressed at how closely he predicts what the plan is going to look like.)
New query:
SELECT TOP 1 ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
JOIN Big_Table BT
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col <= GETDATE()
ORDER BY BT.Sort_Id + 1;
GO
And here is where things went sideways in my demo.
Here is the plan I ended up with.
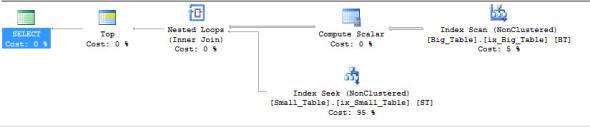
And here is the plan I expected.

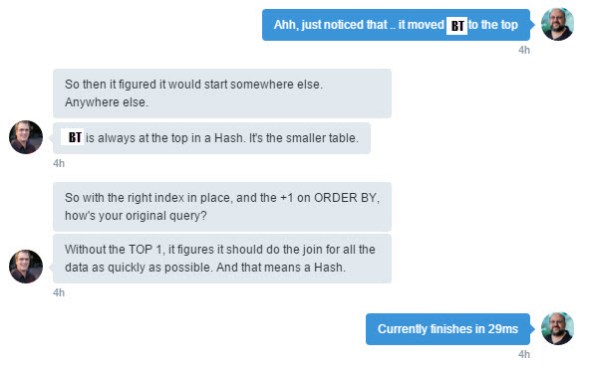
If you look you’ll see that in the plan I got Big_Table is still on top and I get the long running query. In the one I expected (and got at work) Small_Table is on top and the run is sub second. So what’s going on? After a number of frustrating hours and some more help from Rob I finally tracked down the problem. In my demo the Sort_Id is an integer, at work it was a character. And just so you know the column was named “Number” so I think it’s pretty reasonable I was confused. On a side note this is a great example of why the table structures matter when asking a question on a forum.
Ok, so why did the data type mater so much in this case? Well the idea here is to break the sort without actually breaking it. In other words we want the sort column to no longer be SARGable (i.e. ignore the fact that we have an index) but not actually change the sort order (we don’t want to affect our output). Adding a 1 to a character column forces an implicit data type conversion (and as it happens we can no longer guarantee the same order of the data) but SQL is smart enough to know that adding a constant integer to an integer column doesn’t really affect anything.
So obviously adding a +1 isn’t exactly the right answer. So what is? Well in the case of an integer I added RAND(4) (no particular reason for the 4, any int will do). The RAND() function returns a value between 0 and 1, but most importantly, per BOL, Repetitive calls of RAND() with the same seed value return the same results. So the actual row order doesn’t change. But because RAND() is non-deterministic SQL treats the ORDER BY as non-SARGable.
For a character string it’s even easier. Just add an empty string (”). I’m not entirely sure why it causes the sort to be non-SARGable but it does.
New New query:
SELECT TOP 1 ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
JOIN Big_Table BT
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col <= GETDATE()
ORDER BY BT.Sort_Id + RAND(4);
GO
Query plan is the expected one above.
We are doing an index scan on Big_Table which isn’t great since it’s a 1.5 million row table. A seek would be much better but that would require me using the correct index!
-- Drop incorrect index DROP INDEX Big_Table.ix_Big_Table; -- Put index back but in the right direction -- (join, sort rather than sort, join) CREATE INDEX ix_Big_Table ON Big_Table (Join_Id, Sort_Id);
New Query Plan

With a time of around 30ms! Big change from even the seven seconds produced by my first fix.
The rest is just review. I’ve left it here for you to read but I won’t be making any more comments.





Hi, great article,
If you use, for example, TOP 0.01 PERCENT, in the SELECT statement, instead of TOP 1 your query also runs faster and execution plan is OK.
SELECT TOP 0.001 percent ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
JOIN Big_Table BT
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col < = GETDATE()
ORDER BY BT.Sort_Id;
GO
This certainly did work well! Sub second (although not nearly as fast as our final version). My only concern about using a percentage is that if the tables grow enough then the code could break because we end up returning two rows.
This works because you’re telling to count everything first. You could also include COUNT(*) OVER() in the SELECT clause to achieve the same thing, but this would change the output of the query, which generally annoys developers.
True enough. And SQL should not require the nonclus index removed to determine the best query plan. But since it would, we must explicitly specify that SQL use the clustered index to access Big_Table. That is not ideal, but to me it’s better than the alternative of the wrong clustering index, which is vastly more harmful to overall performance than most/all other factors combined.
SELECT TOP (1) ST.Join_Id,
ST.Other_Col,
ST.Other_Col2,
ST.PK_Id,
BT.Sort_Id
FROM Small_Table ST
JOIN Big_Table BT WITH (INDEX(Big_Table__CL))
ON ST.Join_Id = BT.Join_Id
WHERE ST.Where_Col < = GETDATE()
ORDER BY BT.Sort_Id;
Another possibility is to step back and first make sure you have *the best* clustered index on every table, because of the critical nature of clustering on performance. Btw, this is most often *not* on an identity column first. Only after determining *the best* clus index, add non-clus index(es) if you still need them.
For example, for the single query above — which I understand may or may not be indicative of (almost) all query patterns on this table, but for the sake of this exercise will assume it is — try clustering the tables as below and then re-run the query, with and w/out TOP (1):
CREATE UNIQUE CLUSTERED INDEX Big_Table__CL ON Big_Table ( Join_Id, Sort_Id );
CREATE UNIQUE CLUSTERED INDEX Small_Table__CL ON dbo.Small_Table ( Where_Col, PK_Id );
The code reads a good number of rows, but because the clustering is right, the code still runs very quickly, and you don’t have to spend lots of time and index builds to get that performance.
I’m not sure if I’m doing something wrong but when I created the initial test table with the clustered indexes you recommended then ran the initial query I had it still gave me the same “bad” query plan.
Odd. So you removed the existing PRIMARY KEY constraints and created the tables with just the new clustered indexes? Because I got a plan with just seek (and scan) on the small table and just seeks on the big table.
How much of the code did you run? I just ran the initial setup script and the very first version of the query. That means I’m running without the index changes I did later.
I ran with only my clustered indexes in place. That’s part of the point of “the best” clustering indexes, that you need far fewer nonclustered indexes.
Impressive! (49ms on my machine)
There are a few down sides (including the fact that I doubt those CLs are good for inserts) but on the whole very cool.
It depends. Often the new clustering key is generally sequential anyway, such as as datetime of insert (typically by far the best clustering key for logging tables, for example). Or a child table keyed by the ascending parent key (such as items on an order, keyed first by order_id). Finally, keep in mind that (1) a row is inserted only once but read 100x+ after that, so read efficiency ultimately means more and (2) you can slightly reduce the fillfactor and/or reorganize and/or rebuild the table to make up for some fragmentation during insert. My experience shows that insert fragmentation is drastically over-rated when “defaulting” to an identity column. **Never** default a clustering key because it’s the single most critical factor in table performance; rather, always verify carefully select *the single best* clus index possible.
Oh I don’t disagree at all that the CL is one of the most important parts of table design. Or that a good CL can make a HUGE difference (as can a bad one).
The key in what you’re suggesting, Scott, is to remove the index on sort_id. If that index is put back, then the query will use it and performance will tank again. I find it very hard to recommend people remove indexes, because they’re often used for other queries too.
Hi Scott – using an index hint does achieve it, yes. The issue is that the index on sort_id is mistakenly considered more useful than it is. So you either alter the query so that it’s less useful, or you force its hand with a hint. I don’t like index hints for this kind of thing, but if you do, then that’s a great solution too.
[…] Kenneth Fisher has a good case study on tuning with the help of Rob Farley: […]