
Why do DBAs dislike loops?
5August 22, 2019 by Kenneth Fisher
If you started out as a developer you were probably taught how important loops are. They are one of the first handful of things you’re taught about along with conditionals, variables, functions, stored procedures etc. On the other hand, you’ve probably noticed that database professionals tend not to like them. Now, personally, I have no problems with loops when you need them, but only when you need them.
So why do data people tend to avoid (or even actively dislike) loops? (Can you say cursor anyone?). Scaleability! Loops just don’t scale well. A loop that is fast at 100 loops is going to take twice as long at 200 loops, five times as long at 500 loops and one hundred times as long at 10,000 loops. That’s a problem in the database world when at 10,000 rows a table is still considered small and depending on your experience a mid-sized table might be 1,000,000 rows or more. As in all things I like examples, so here’s a simple one.
I’m creating a table with an identity column (the primary key/clustered index) and a date column. I’m going to record times spent updating each row one at a time and just updating the entire table. Then I’m going to add 10 rows and run again, 10 rows and run again, etc until I have 7500 rows. (Not a lot but it takes a while to run.) Quick note to everyone who reads this and thinks “But …”. I’m aware this is a really simple example. If you have buts that you think will significantly change the outcome feel free to run a test yourself and if by some odd chance (unlikely but hey, could happen) feel free to put the results in the comments, or even better blog them and link the blog in the comments :).
-- Create work table & log table CREATE TABLE LoopSpeed ([RowCount] INT, LoopTimeInMS INT, BatchTimeInMS INT); CREATE TABLE LoopSpeedTest (Id INT NOT NULL IDENTITY(1,1) PRIMARY KEY, ADate DATETIME); GO DECLARE @RowCount INT = 0; DECLARE @LoopCount INT = 0; DECLARE @StartTime DATETIME, @EndTime DATETIME DECLARE @LoopTimeInMS INT, @BatchTimeInMS INT -- 750 loops at 10 row increments. WHILE @RowCount < 7501 BEGIN -- Add 10 rows INSERT INTO LoopSpeedTest (ADate) VALUES (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()), (GetDate()); SELECT @RowCount = COUNT(1) FROM LoopSpeedTest; SET @LoopCount = 0; SET @StartTime = GetDate(); -- Loop that updates each row in the table one at a time. WHILE @LoopCount < @RowCount BEGIN SET @LoopCount = @LoopCount + 1; -- Update one row. UPDATE LoopSpeedTest SET ADate = GetDate() WHERE Id = @LoopCount; END -- Get duration of loop; SET @LoopTimeInMS = DATEDIFF(millisecond,@StartTime,GetDate()); SET @StartTime = GetDate(); -- Update all of the rows in the table in a batch. UPDATE LoopSpeedTest SET ADate = GetDate(); -- Get duration of batch; SET @BatchTimeInMS = DATEDIFF(millisecond,@StartTime,GetDate()); INSERT INTO LoopSpeed VALUES (@RowCount, @LoopTimeInMS, @BatchTimeInMS); END
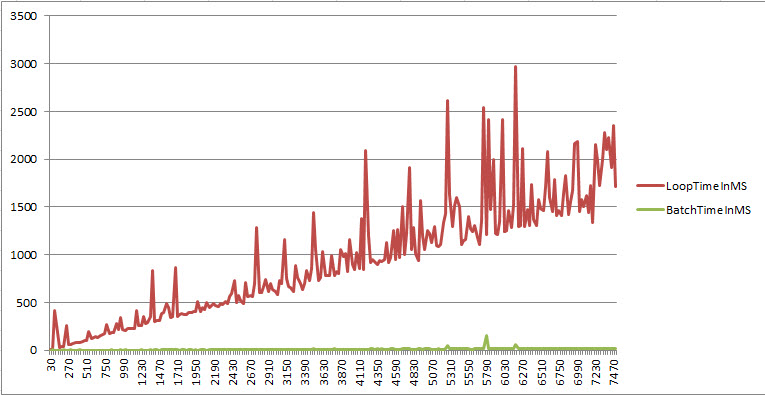
First let me point out that I’m running this on a very old, cheap laptop and I’m measuring milliseconds. It doesn’t take much to get wild variations in the numbers. That’s why the loop time has such wild variations at times. That said, I’m sure you notice the slow but steady increase in time taken to run the loop. Now imagine if I wanted to run an update over a million rows? We’d no longer be measuring in milliseconds, we’d be measuring in minutes or even hours. Lastly, I want you to notice that pretty flat line along the bottom. That is the very very slow increase in time that the batch update takes. At 10 rows it was approximately 0ms and at 7500 it was 20. Yes, the duration does increase with the number of rows. If nothing else, I/O does take time after all. But SQL is built to handle large numbers (these are really pretty minuscule numbers for SQL to be honest) of rows at a time.
Let me give you an analogy. Let’s say we are baking a cake and I ask you to go to the store to get the ingredients.
- 1/2 cup unsalted butter, softened
- 1 1/2 cups sugar
- 3 large eggs
- 2 1/4 cups all-purpose flour
- 1 teaspoon salt
- 3 1/2 teaspoons baking powder
- 1 1/4 cups whole milk
- 1 teaspoon vanilla
- 2 1/2 cups buttercream frosting
I start by asking you to get me the butter. You run to the store, get the butter and come back. Then I ask for some sugar. Then eggs, etc. Assuming you don’t just get frustrated and start yelling at some point it’s going to take a while right?
But if I had you that entire list, you run to the store, get each item and come back. Much faster right? And if I double the length of the list it’s going to take longer to get but not nearly as long as if I ask you to go to the store for each of the additional items one at a time. (Fortunately computers are very patient and don’t actually get angry about being asked to do one thing at a time.)
Conclusion
There is a good reason that database professionals tend to avoid loops. They are slow, inefficient, and scale poorly when compared to batch processing. That said, you still need to know how to use them as occasionally you have no choice. A simple example is changing the read/write status of every database on the instance. Those situations are pretty rare though. Batches really are the way to go if at all possible.





I agree with you that loops are generally bad form for SQL programming. However, I look on it as a Brown M&M test – if a SQL Programmer is using an unnecessary loop, they do not understand the way SQL works as well as they should. It is a different skill to regular procedural programming and some people just don’t think like that.
Having said this, I find that loops are needed more often than I would like if you are using transactions.
I think that It is more efficient overall to use a loop to start a transaction, update one record in Table A, update a few records in Table B and then commit the transaction, rather than to start the transaction, update all of Table A, all of Table B and then commit the huge resulting transaction – the locks needed for a bulk update are more likely to interfere with other processes than if you can lock a few records at a time.
The loop might take 10 minutes instead of 10 seconds but, for most purposes, this is acceptable. Indeed, if the loop takes hours, you can potentially stop it as business hours approach and then continue the next night from where you left off. It will be slower but it is more reliable and resilient and has less impact on other processes happening on the system.
That’s going to depend on the usage. It’s not a bad idea but doing that on an active OLTP system could bring it to it’s knees depending on what’s going on. I’ll agree I’ve used loops to break up large transactions that are using too much log space, or taking too long, you just have to be careful there too.
Again, loops are good things, when used carefully and at the appropriate time. And yes, part of the point of the post was for developers who learn how wonderful loops are, but don’t realize they can be detrimental in database programming.
Here’s one interesting aspect of Loop coding we recently found, which is another reason loops should be avoided.
If you are running a server-side SQL trace, and say you do have what appear to be appropriate filters on things like (Duration > 5 seconds, or Reads > 100000). If you have the server-side filtered trace on, and it hits some loop logic that isn’t really even doing any SQL commands, just the fact that the trace is running, will bog down the server, rather severely too. Talking about loops that have a good amount of iterations, like 100,000+ not just a handful of loop iterations. So, it’s not that the traces were capturing anything, as the commands didn’t hit the filter limits of Durations or Reads, just the loops need to check each statement in the loop to see if it is above the trace filter criteria. Kill the trace and the possible poorly coded loops speed up immediately. We then found that the newer way of SQL tracing, using extended events, does NOT put such a severe strain on the server during loop processing.
*nod* I’d call that more of a problem with profiler than with loops themselves but it’s still a very good warning.
and this wasn’t with Profiler, which is the GUI tool users have to do SQl traces across the network that can be resource intense. Was talking about what is usually thought of to be a safer less intense tracing method, a SQL server-side trace. Both choke on loops, Profiler and server-side traces. We have since changed any server side traces to use extended events, and have much less performance issues with loops. I brought up the relationship of loops and SQL traces, because that is the worst thing I’ve seen with loops, you test and it’s ok, then one day someone sets up a server-aside filtered trace that normally would be ok. But it crushes the entire server.